Editor's Note

Today is White Dew; the first summer vacation for Shenzhen University of Advanced Technology (SUAT)'s inaugural undergraduates is ending, and tomorrow begins sophomore year studies and life.
Looking back on this summer, besides resting body and mind, many SUAT students immersed in labs with mentors, engaged in social practice and industry surveys, or visited prestigious international universities for exchanges... truly a"high-energy" vacation.
Today, the"High-Energy Summer at SUAT" column launches; the first edition introduces how 2024 undergraduate Yang Xiaodong and his team turned hobbies into visible achievements through lab immersion this summer, winning national second prize.

Yang Xiaodong
2024 Undergraduate at SUAT
This summer, my team and I brought the"AI Comic Assistant" project from provincial first prize to the national second prize podium!
The initial idea for this project was simple: My teammates and I are anime fans and wanted to try using text-to-image models to generate comic strips.
Preparing for the Guangdong provincial competition in the first half of the year, we first screened development platforms, ultimately choosing user-friendly and open-source ComfyUI and Dify to build an interactive comic generation platform. Both tools are visual workflow orchestration, making development relatively low difficulty at this stage. To aim for provincial first prize, I proposed shifting core R&D from text-to-image to text-to-video models, abandoning Dify agent platform and developing in native Python environment to maximize Python's rich community ecosystem resources.
Problems soon arose: how to land text-to-video technology into differentiated applications? Mainstream text-to-video models then stably generated videos 5-10 seconds long—what could such short durations do? Thus, extending effective video duration became our primary goal.
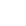
Though many feasible schemes, limited by project funding, high-cost methods like "real-time text-to-video generation" couldn't be implemented."Since real-time generation doesn't work, can we pre-cache animations and connect them? " This idea wasn't new; many open-source projects were trying it then, mostly in virtual streamer fields, caching mainly by reusing generated video frames. We took "caching video frames" as entry point, clarifying the overall framework of "anime character motion control system": First generate diverse motion videos like standing, squatting, sitting, walking for a single anime character, then bind character behaviors to instructions via control net, making it "understand" our commands and respond—like an interactive virtual desktop pet.
The key deciding competition outcome was control model training and deployment. Looking back, provincial competitions valued innovative ideas more, with relatively lenient requirements for demo effects and model maturity. Precisely because the "anime character motion control" idea was novel enough, we qualified for nationals. But entering nationals, my teammates and I agreed: We must polish this "lab-stage prototype" into a landable mature application.
First-generation virtual desktop pet: no dialogue window, console full of debug info
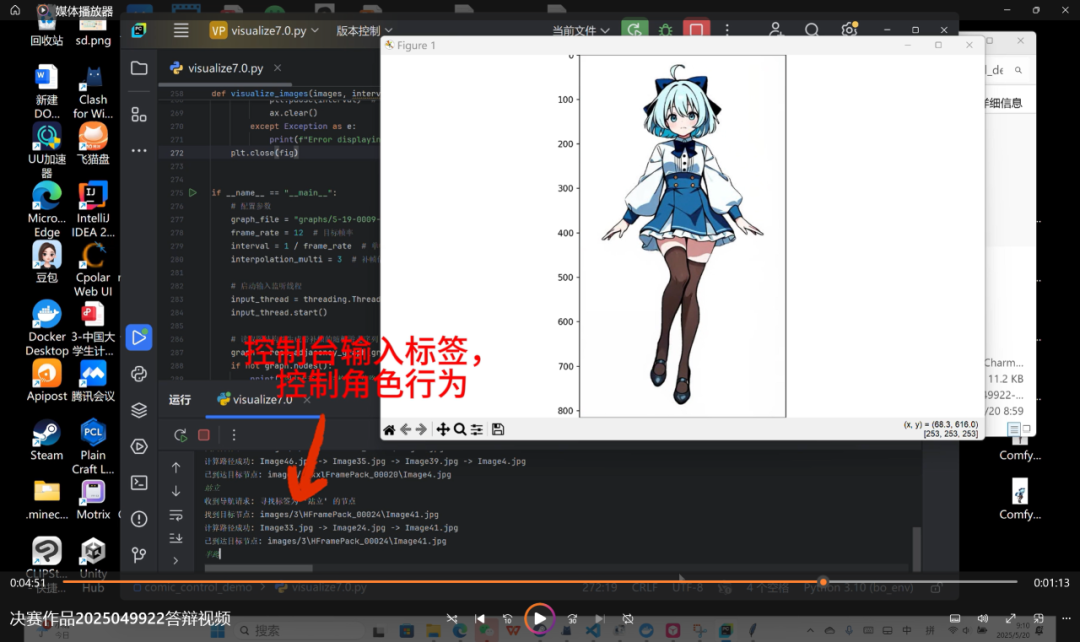
So we restarted Dify platform, cramming Python UI orchestration and web development knowledge, fully advancing product iteration: First optimize control model, significantly reducing motion "frame skipping" by increasing training samples and neural network layers; second reconstruct interaction design, simplifying UI, adding dialogue window, removing redundant console debug info; finally connect large language model replacing "hard-coded" instruction labels, achieving direct natural language dialogue with virtual characters.
National competition virtual desktop pet: UI optimized, large language model connected, smoother images and motions
The national host city Changchun gave me a first impression of warmth. Along the way, taxi drivers with hearty northeastern accents always proudly introduced local attractions and food.
On final defense day, I was very nervous, but an image generation expert judge didn't ask tricky questions, instead providing optimization directions and suggestions professionally—this tolerance and encouragement from industry seniors surprised and moved me.
After defense, my teammates and I spent half a day visiting Changbai Mountain Tianshi; standing at the top, clear blue skies. At awards, hearing "national second prize" announced for our project, my mind instantly flashed summer scenes: Dorm lights on all night, repeatedly debugging failed code, coffee keeping us up... those dawn-staying days finally had the most perfect answer.
Our advisor, Assistant Professor Han Ruize from the College of Computing Science and Control Engineering, always says: "Interest is the greatest motivation. " This summer I understood better:interest alone isn't enough; persistence in gnawing hard bones is needed. From initially only reproducing code from papers to now autonomously designing model architectures and labeling samples, I not only mastered full project development flow but learned calm problem-solving—change ideas if budget short, repeatedly test if model fails; solutions always outnumber difficulties.
Competition ended, but "AI Comic Assistant" development continues. In the next half month, my team and I continued exploring improving anime character motion accuracy via human keypoint detection technology.
To overcome this, I searched Bilibili for materials, learned related courses, systematically understood human keypoint Pose model training methods, then prepared anime human keypoint dataset. Soon, I deeply experienced the difficulty of anime human keypoint data labeling: Low labeling quality makes models almost unusable; quality needs repeated testing comparisons to verify.
Dataset ready, we entered model framework selection stage. Under MMpose framework, we compared YOLOv11-X and RTMPose-X; after multiple debugging rounds, found RTMPose-X's "heatmap localization" better suits anime characters—not directly locating single keypoints but identifying via probability distribution, higher tolerance for exaggerated anime limbs.

Human Keypoint Detection Results and Probability Distribution Heatmap
To further optimize model accuracy, I personally labeled keypoints on 75 anime character samples, split 6:1 training/validation sets, watching model train 100 epochs. At 80th epoch, model test accuracy reached 0.9134 COCO/AP, basically meeting subsequent development needs.
Virtual digital industry and digital economy are important future economic directions; many anime fans and tech developers strive for innovation in this field. Looking back on this summer, I am no longer the freshman who only knew anime but truly a developer standing in the digital economy wave.
This summer, perfect ending with flower scatter.
 CN
CN